
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 3기
- ChatGPT
- AIVLE
- TRANSFORMER
- ML
- 생성형
- hyperclovaX
- GPT4
- naver
- Meta
- GPT-4
- 네이버
- AI
- Stable Diffusion
- KT
- deeplearning
- 인공지능
- KoGPT
- SKT
- 딥러닝
- gpt
- 생성형 AI
- LLM
- LLaMA
- GPT-3.5
- nlp
- generative
- SearchGPT
- OpenAI
- Today
- Total
Ttoro_Tech
[AIVLE_3기]_12주차_AI_SPARK_CHALLENGE 본문
https://aifactory.space/task/2226/overview
제4회 2023 연구개발특구 AI SPARK 챌린지 - 공기압축기 이상 판단
산업용 공기압축기의 이상 유무를 비지도학습 방식을 이용하여 판정
aifactory.space
AIVLE 첫 공모전 참여
1반과 2반에서 마음이 맞는 분들과 함께 4인 팀을 이뤄 첫 공모전에 참가함
목표
산업용 공기압축기의 이상 유무를 비지도학습 방식을 이용하여 판정
비지도 학습
머신러닝 유형에는 3가지가 존재함
- 지도학습(Supervised Learning)
- 준지도학습(Semi-supervised Learning)
- 비지도학습(Unsupervised Learning)
이중 처음으로 비지도학습을 목표로 한 공모전
비지도 학습(Unsupervised Learning)
비지도 학습은 기계가 미분류 데이터만을 제공 받음
데이터에 정답인 Label 값을 가지지 않음
기계의 구조
- 클러스터링 구조(Clustering structure)
- 저차원 다양체(Low-dimensional manifold)
- 희소 트리 및 그래프(A sparse tree and graph) 등
데이터의 기저를 이루는 고유 패턴을 발견하는 문제
클러스터링(Clustering)
- 특정 기준에 따라 유사한 데이터 사례들을 하나의 세트로 그룹화함
- 전체 데이터 세트를 여러 그룹으로 분류하기 위해 사용
- 사용자는 고유한 패턴을 찾기 위해 개별 그룹 차원에서 분석을 수행할 수 있음
23.04.18. 기준 Score 0.958
1. AutoEncoder
- 단순히 입력을 출력으로 복사하는 신경망
- 어떻게 보면 간단한 신경망처럼 보이지만 네트워크에 여러가지 방법으로 제약을 줌으로써, 어려운 신경망을 만듦
- 이러한 제약조건으로 오토인코더가 단순히 입력을 바로 출력으로 복사하지 못하도록 방지
- 데이터를 효율적으로 표현(Representation)하는 방법을 학습하도록 제어
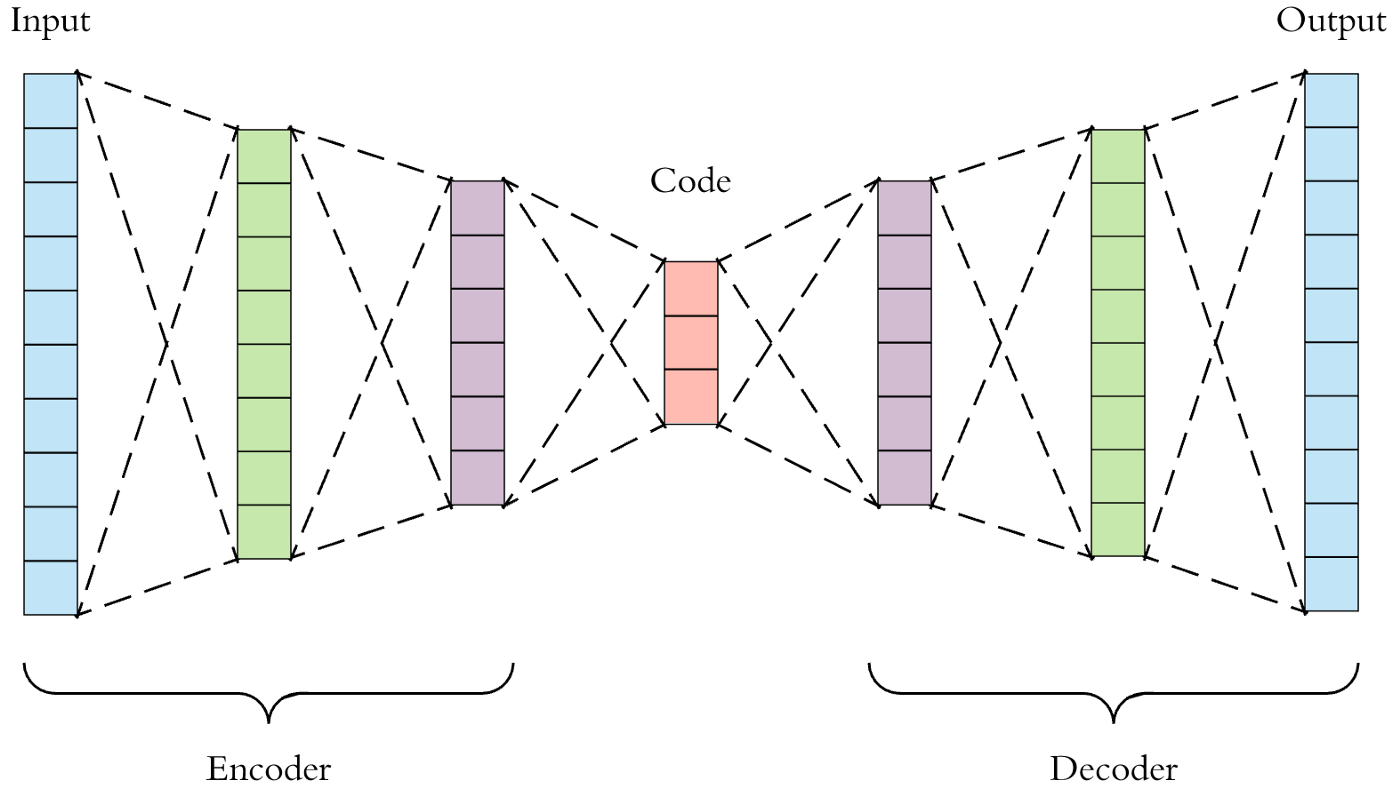
AutoEncoder의 구성
- 인코더(Encoder) : 인지 네트워크(Recognition Network)라고도 하며, 입력을 내부 표현으로 변환
- 디코더(Decoder) : 생성 네트워크(Generative Network)라고도 하며, 내부 표현을 출력으로 변환
- 오토 인코더는 입력을 재구성하기 때문에 출력을 재구성(Reconstruction)이라고도 하며, 손실함수는 입력과 재구성(output)의 차이를 가지고 계산
2. Deep SVDD
- 정상 데이터만을 학습하여 Anomaly Detection을 하는 Semi-Supervised 방식
- 과거 Anomaly Detection(AD)의 비정상 탐지
- One-Class SVM
- Kernel density estimation
- 하지만 고차원에서 좋은 성과를 내지 못함
- 좋은 성과를 내기 위해 Feature Engineering을 하는 부가적인 노력이 필요했음
- DeepLearning을 사용한 AD 방법
- AutoEncoder - 하지만 재구축 오차에 의존한 방법
Deep Support Vector Data Description(Deep SVDD) [paper]
두 연구에 영감을 받아 진행
- kernel-based one-class classification
- minimum volume estimation
Deep SVDD의 목적
딥러닝을 기반으로 학습한 데이터의 Feature Space를 통해 정상 데이터를 둘러싸는 가장 작은 구를 찾는 것이 목적
One-Class SVM(OC-SVM)
Mapped Data를 가장 잘 분리할 수 있도록 Feature Space에서 최대 마진이 초평면, w를 찾는 것
$$\min_{R,p,\xi} \frac{1}{2} ||w||^2_{F_k} - p + \frac{1}{vn}\sum^{n}_{i=1}{\xi_i}$$
Support Vector Data Description (SVDD)
- Feature space, $F_k$의 정상 데이터가 중심점 $c \in F_k$, 반지름 $R > 0$의 구 경계면 안에 들어오도록 하는 것
- 가장 작은 구, 즉 $R$이 작은 구를 찾는 것이 목적
$$\min_{R,c,\xi} R^2 + \frac{1}{vn}\sum_{i=1}{\xi_i}$$
- 즉, 정상 데이터를 포함할 수 있는 가장 작은 구, R을 찾음
- 동시에 Slack Variable을 통해 soft boundary를 허영하고, v를 통해 slack variable과 구의 크기 간의 trade-off를 조절함
Deep SVDD
- 기존의 kerenl-based SVDD는 정상 데이터를 포함할 수 있는 가장 작은 구를 찾는 것이 목적
- Deep SVDD의 경우 딥러닝 모델을 통해 data를 새로운 Representation으로 만듦
- 가장 작은 구를 만드는 과정과 연결되어 학습
- 기존 데이터 X를 새로운 표현 F로 표현할 수 잇는 딥러닝 Weights를 W
- 이 때, 중심점 c, Radius R를 최소로하면서 정상을 포함할 수 있는 구를 학습할 때 W로 같이 연결하여 학습
Soft-Boundary Deep SVDD의 목적함수
$$\min_{R,W} R^2 + \frac{1}{vn}\sum^{n}_{i=1}max\{0, ||\phi(x_i;W) - c||^2 - R^2\} + \frac{\lambda}{2}\sum^{L}_{l=1}||W^l||^2_F$$
https://excelsior-cjh.tistory.com/187
08. 오토인코더 (AutoEncoder)
이번 포스팅은 핸즈온 머신러닝 교재를 가지고 공부한 것을 정리한 포스팅입니다. 08. 오토인코더 - Autoencoder 저번 포스팅 07. 순환 신경망, RNN에서는 자연어, 음성신호, 주식과 같은 연속적인 데
excelsior-cjh.tistory.com
https://blog.roboflow.com/what-is-an-autoencoder-computer-vision/
What is an Autoencoder?
An autoencoder is an artificial neural network used to learn data encodings in an unsupervised manner.
blog.roboflow.com
https://blog.naver.com/winddori2002/222142873877
[바람돌이/딥러닝] Deep SVDD 논문 및 코드 리뷰
안녕하세요 오늘은 anomaly detection 논문 중 하나인 Deep One-Class Classification에 대해 정리하고...
blog.naver.com
'Data Projects' 카테고리의 다른 글
| [한국철도999_5위]_AIFactory_철도 인공지능 대회 (0) | 2023.09.12 |
|---|---|
| [LG Aimers 3기]_온라인 채널 제품 판매량 예측 AI 온라인 해커톤 (0) | 2023.08.31 |
| [AIVLE_3기]_16주차_Dacon_도배 하자 유형 분류 AI 경진대회 (0) | 2023.05.24 |
| [AIVLE_3기]_15주차_AI_SPARK_CHALLENGE(2탄) (0) | 2023.05.09 |



