
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- KoGPT
- TRANSFORMER
- GPT-4
- KT
- LLaMA
- generative
- OpenAI
- GPT4
- deeplearning
- 생성형
- gpt
- naver
- Stable Diffusion
- 생성형 AI
- AI
- 딥러닝
- LLM
- 3기
- 네이버
- 인공지능
- GPT-3.5
- SearchGPT
- hyperclovaX
- AIVLE
- ChatGPT
- nlp
- SKT
- Meta
- ML
- Today
- Total
Ttoro_Tech
[Technical Interview]_자기 반성의 방_1~3 본문
기술 면접
취업 준비를 하면서 다양한 기술 면접을 보았고, 답변을 하면서도
- 내가 정말 그 기술에 대해 잘 알고 있는가,
- 내가 쓴 기술을 실무에 쓸 수 있을 만큼 잘 이해하고 있는가
에 대해 자기 반성을 하게 되었다.
해당 게시글은 면접을 볼 때마다 업데이트 될 예정이며, 게시글이 길어지면 1탄, 2탄 등
나뉘게 될 것 같다.
자기 반성의 공간 같은 곳으로, 회사는 비공개로 작성될 것 같다.
1. Git을 통한 협업을 하셨다고 하셨는데, pull request는 사용하지 않으셨나요?
- 사전 지식 Fork와 Pull request
Fork
배경)
다른 사람의 프로젝트가 마음에 들어, 같이 프로젝트에 참가해, 기여자 역할을 하고 싶다.
하지만 기여를 하기 위해서는 프로젝트의 관리자가 나를 기여자로 등록해야한다.
그러나 모든 사람을 기여자로 등록하기는 어려운 것이 사실이다.
해결방법)
이때 사용할 수 있는 것이 Fork
마치 식사를 할 때 사용하는 Fork와 같이 다른 사람의 repository를 내 github로 가져오는 것
이때 주의 할 점은 Clone과의 차이점이다.
Fork : 내 원격 저장소에 복사하는 것
Clone : 내 로컬 저장소에 복사하는 것
Pull Request
배경)
Fork를 통해 가져온 프로젝트를 로컬에서 수정한 후 이것을 원래 프로젝트 관리자가 수정된 것을 반영했으면 좋겠다 라는 생각이 든다.
해결 방법)
먼저 로컬에서 작업(수정)한 repository를 내 github에 commit하고 이것을 원래 프로젝트 관리자에게 Pull Request를 보내는 것
그러면 프로젝트 관리자는 Code review를 통해 코드를 확인하고, 문제가 없다면 Main branch에 Merge하는 방식으로 프로젝트에 기여하는 것
최종 정리
Pull Request(PR)
내가 수정한 코드가 있으니, 내 branch를 가져가 검토 후 병합해달라고 요청하는 것
PR을 통해 코드 충돌을 최소화, push 권한이 없는 Open Source 프로젝트에 기여할 때 많이 사용
답변 정리
- 네, PR을 사용해본 경험이 있습니다. Orin Project를 진행하면서 서로 branch를 만들어 작업을 수행하였으며, 작업이 끝난 팀원은 branch를 Commit하고, 코드 리뷰 후에 문제가 없을 경우 Pull Request를 통해 메인 Project Repository에 Merge 하여 협업을 수행했습니다.
2. Backend 작업 중 Django를 많이 사용하셨는데, Django의 특징과 장단점에 대해 설명해주실 수 있을까요?
- 사전 지식 Django
Django는 Python으로 제작된 Open Source Web FrameWork
Django로 만들어진 대표적인 사이트로는 Instagram, 핀터레스트, 히어로 코리아, 화해(버드뷰), SendBird(채팅 API) 등이 있다.
Django 특징
한국에서 많이 사용하는 Spring(MVC)과 달리 MTV 패턴을 가지고 있다.
| Django | Spring | |
| DB와 Data를 관리 하는 곳 | Model | Model |
| 실제로 보여주는 Interface | Template | View |
| Model과 Interface를 연결하는 곳 | View | Controller |
특히 같은 단어인 View의 경우 역할이 다르므로 주의해서 봐야한다.
강력한 ORM(Object Relational Mapping)
ORM은 객체와 관계형 DB를 연결해주는 개념
생성한 클래스를 SQL문으로 자동 변환하여 데이터를 다룰 수 있음
SQL을 사용하지 않고도 DB의 데이터를 관리할 수 있게 됨
관계형 DB를 객체처럼 볼 수 있게하여, 개발자가 로직 작성에 집중하도록 도와줌
소스코드의 변경 사항을 자동으로 반영
Django는 자동으로 .py 형식의 file 변동을 감시함
변경이 감지되면 이를 자동으로 반영
이는 코드를 변경할 때마다 수동으로 웹서버를 재시작할 필요가 없음
Python 기반 웹 프레임 워크
python에서 가능한 모든 동작이 가능함, 이는 강력한 라이브러리를 사용할 수 있다는 장점이 있음
장점
python을 기반으로 하고 있으므로 진입장벽이 낮은 편임
admin, login 등 이미 구현되어 있는 기능들이 많아 쉽게 사용할 수 있음
MVT 형태로 작업을 수행할 수 있어 각각의 App별로 분업 수행이 용이함
URL을 함수와 1:1 매칭이 가능하여 URL 디자인이 매우 편리함
단점
이미 만들어진 부분이 많아 세세한 커스터마이징에는 어려움이 많음
파이썬 기반으로 다른 Web Framework에 비해 속도가 느림
- 답변 정리
넵, 잘 만들어진 AI 모델 등을 빠르게 배포하기 위해 Web을 기반으로한 서비스를 제공하고자 django를 사용했습니다. django의 장점으로는 python 웹프레임워크로 python을 활용한다면 누구나 쉽게 접근할 수 있다는 용이함이 있습니다. 뿐만 아니라 MVT로 구성된 점으로 개별적인 app 형식으로 개발이 가능하여 분업을 통해 작업을 수행할 수 있다는 장점이 있습니다. 또한 admin, login 등 이미 구현되어 있는 모듈이 많아 다른 로직 구현에 집중할 수 있다는 장점이 있었습니다. 하지만 django는 단점 또한 존재합니다. 다른 Web framework에 비해 느리며, 이미 구현되어 있는 기능이 많아 세부적인 기능 커스터마이징에는 어려움이 있습니다.
3. 다양한 가중치 초기화(Weight Initalization) 방법에 대해 알고 있습니까?
- 배경지식 Random Init, LeCun Init, Xavier Init, He Init
초기 가중치 설정
딥러닝 학습에 있어 초기 가중치 설정은 매우 중요한 역할을 함
가중치 설정을 잘못 설정하게 될 경우 기울기 소실(Vanishing Gradient), 기울기 폭발(Exploding Gradient) 등 여러 문제를 야기하게 됨
또한 이는 Global minimum을 찾아가는 것이 아닌 Local minimum에 수렴할 가능성이 커지게 됨
다양한 가중치 초기화 방법
- Zero Initialization
가중치를 0으로 초기화 시킬 경우 역전파 과정에서 각 가중치의 update가 동일하게 일어난다. 이는 Layer와 Node를 여러개 만든 의미를 잃게 되며 좋은 방법이 아니다.
- Random Initialization
그렇다면 정규분포를 따르는 랜덤한 가중치로 초기화하면 괜찮지 않을까라는 생각이 든다. 괜찮은 방법이지만 이러한 방법을 통해 가중치 초기화를 하게 될 경우 하나의 문제가 생긴다. 하나의 예시로 모델의 활성화 함수로 Sigmoid를 사용했을때를 들어보자. 표준편차를 1로 설정하고 실험한 결과는 0과 1에 가까운 값만 출력되는 것을 확인할 수 있다.

그러나 이를 미분한 값은 0에 가깝기 때문에 기울기 소실(Gradient Vanishing)이 발생한다. 그렇다면 양 끝에 몰리지 않게 표준편차를 0.01로 할 경우를 확인해보자.
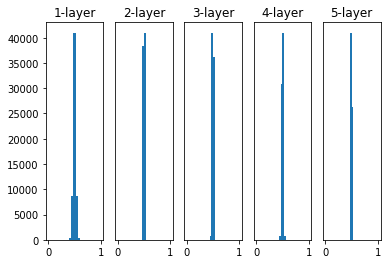
양 끝에 몰리는 현상은 줄었지만, 출력값의 대부분이 0.5 주변에 몰리는 것을 확인할 수 있다. 이는 기울기 소실은 줄였지만, Zero Init과 같이 출력값이 비슷해지면 노드를 여러개로 구성하는 의미가 사라지는 것이므로, 단점이 있음을 확인할 수 있다.
- Xavier Initialization(재비어, Glorot 글로럿)
Random Init에서 발생하던 문제를 해결한 방법이다.
여기서는 고정된 표준편차를 사용하지 않음
이전 은닉층의 노드 수에 맞춰 변화시키는 방법.
이전 은닉층의 노드의 개수가 n개이고, 현재 은닉층의 노드가 m개 일때,
$$ \sigma = \frac{2}{\sqrt{n+m}}$$
을 표준편차로 하는 정규분포로 가중치를 초기화 함

이는 이전 두 방법보다 훨씬 더 고르게 퍼져있음을 확인할 수 있음
고정된 표준편차를 사용하는 것보다 더 강건하게 학습되는 것을 확인할 수 있음
재비어 초기화 방법의 경우 비선형 활성화 함수 Sigmoid, Tanh에서 잘 활용됨.
그러나 DL에서 많이 사용되는 ReLU 함수의 경우 문제가 발생함
- He Initialization
재비어 초기화 기법은 강건한 학습이 가능하도록 도와줬지만, ReLU의 경우 Output이 0으로 수렴하는 현상이 있었음
이를 해결하기 위해 나온 방법이 He 초기화 방법
재비어 초기화 방식과 동일하게 이전 은닉층의 노드의 개수가 n일 때
$$ \sigma = \sqrt{\frac{2}{n}} $$
를 표준편차로 하는 정규분포로 초기화 함


재비어 초기화 방식의 경우 처음에는 분포가 골고루 분포되어 있지만, 층이 깊어질 수록 점점 분포가 치우쳐지는 것을 확인할 수 있음. 그러나 He 초기화를 사용하면 층이 깊어지더라도 모든 활성값이 고른 분포를 보이는 것을 확인할 수 있음
- LeCun Initialization
SELU (Scaled ELU) 활성화 함수를 사용한 모델의 성능이 잘 나오면서 사용되는 초기화 방법.
완전 연결 층만 쌓은 신경망을 만들고, 모든 은닉층이 SELU 활성화 함수를 사용하면, 네트워크가 자기 정규화가 된다고 주장
조건
- 입력 특성은 반드시 표준화($\mu = 0, \sigma=1$)가 되어야 한다.
- 또한 모든 은닉층은 Lecun 정규 분포로 초기화
이전 layer의 input 노드 수가 n일 때
$$ \sigma = \sqrt{\frac{1}{n}} $$
답변 정리
- 넵, 가중치 초기화 방법에는 zero 초기화, Random 초기화, Lecun 초기화, Xavier 초기화, He 초기화 방식 등이 있습니다. 기존 Random 초기화의 경우 고정된 표준편차로 인해 기울기 소실이 일어나는 문제점이 있었습니다. 이를 해결하기 위해 동적인 가중치 초기화 방법이 필요했고, 재비어 초기화, He 초기화 등 이전 레이어의 히든 노드 수를 고려한 표준편차를 구하여 가중치 초기화에 사용했습니다. 재비어의 경우 비선형 (sigmoid, Tanh) 활성화 함수 등이 효과적이며, He의 경우 ReLU를 사용한 Model에서 효과적입니다. 뿐만아니라 최근 SELU 함수를 사용한 모델의 경우 Lecun 초기화를 활용하여 모델의 성능을 높인 방법도 있습니다.
Reference
https://inpa.tistory.com/entry/GIT-⚡️-깃헙-PRPull-Request-보내는-방법-folk-issue
https://yngie-c.github.io/deep%20learning/2020/03/17/parameter_init/
'Tech Plus' 카테고리의 다른 글
| [Technical Interview]_자기 반성의 방_4~5 (0) | 2024.03.10 |
|---|---|
| [HyperCLOVA X]_Naver_DAN23_Conference (0) | 2023.08.25 |
| [AIVLE_3기]_16주차_KoAlpaca 세미나(goorm_commit) (0) | 2023.05.24 |
| [세미나_goorm]_‘KoAlpaca’_개발기 (0) | 2023.05.18 |
| [세미나]_AIFactory_LLM기반_챗봇_만들기 (0) | 2023.05.09 |


